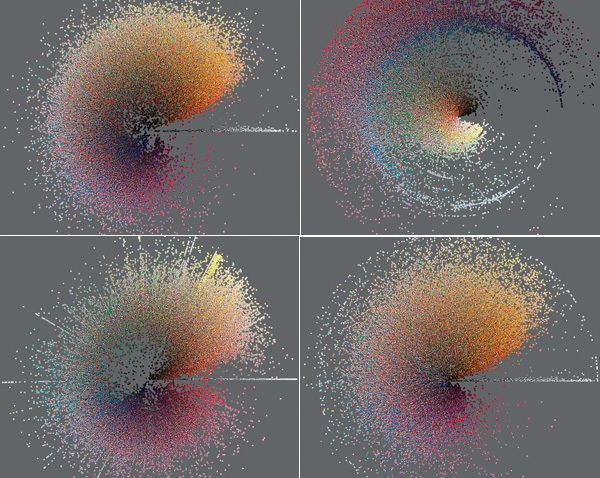
Phototrails.net
The author and several colleagues studied cultural differences using these computerized patterns of Instagram postings—arranged by hue and brightness—from Tokyo, New York, Bangkok, and San Francisco.
In 2002, I was in Cologne, Germany, and I went into the best bookstore in the city devoted to humanities and arts titles. Its new-media section contained hundreds of books. However, not a single title was about the key driver of the “computer age": software. I started going through indexes of book after book: No “software.”
Yet in the 1990s, software-based tools were adopted in all areas of professional media production and design. In the 2000s, those developments have made their way to the hundreds of millions of people writing blogs and tweeting, uploading photos and videos, reading texts on Scribd, and using free tools that 10 years earlier would have cost tens of thousands of dollars.
Thanks to practices pioneered by Google, the world now operates on web applications that remain forever in beta stage. They can be updated anytime on remote servers without consumers having to do anything—and in fact, Google is revising its search-algorithm code as often as 600 times a year. Welcome to the world of permanent change—a world defined not by heavy industrial machines that are modified infrequently, but by software that is always in flux.
Software has become a universal language, the interface to our imagination and the world. What electricity and the combustion engine were to the early 20th century, software is to the early 21st century. I think of it as a layer that permeates contemporary societies. If we want to understand today’s techniques of communication, representation, simulation, analysis, decision making, memory, vision, writing, and interaction, we must understand software.
But while scholars and media and new-media theorists have covered all aspects of the IT revolution, creating fields like cyberculture studies, Internet studies, game studies, new-media theory, and the digital humanities, they have paid comparatively little attention to software, the engine that drives almost all they study.
It’s time they did.
Consider the modern “atom” of cultural creation: a “document,” i.e. content stored in a physical form delivered to consumers via physical copies (books, films, audio records) or electronic transmission (television). In software culture, we no longer have “documents.” Instead, we have “software performances.”
If you are a scholar working inside Google or Facebook, you have a major advantage over colleagues in academe.
I use the word “performance” because what we are experiencing is constructed by software in real time. Whether we are exploring a website, playing a video game, or using an app on a mobile phone to locate nearby friends or a place to eat, we are engaging with the dynamic outputs of computation.
Although static documents may be involved, a scholar cannot simply consult a single PDF or JPEG file the way 20th-century critics examined a novel, movie, or TV program. Software often has no finite boundaries. For instance, a user of Google Earth is likely to experience a different “earth” every time he or she uses the application. Google could have updated some of the satellite photographs or added new Street Views and 3D buildings. At any time, a user of the application can also load more geospatial data created by other users and companies.
Google Earth is not just a “message.” It is a platform for users to build on. And while we can find some continuity here with users’ creative reworking of commercial media in the 20th century—pop art and appropriation, music, slash fiction and video, and so on—the differences are larger than the similarities.
Even when a user is working only with a single local media file stored in his or her computer, the experience is still only partly defined by the file’s content and organization. The user is free to navigate the document, choosing both what information to see and the sequence in which to see it. (In Google Earth, I can zoom in and out, switching between a bird’s-eye view of the area, and its details; I can also switch between different kinds of maps.)
Most important, software is not hard-wired to any document or machine: New tools can be easily added without changing the documents themselves. With a single click, I can add sharing buttons to my blog, thus enabling new ways to circulate its content. When I open a text document in Mac OS Preview media viewer, I can highlight, add comments and links, draw and add thought bubbles. Photoshop allows me to save my edits on separate “adjustment layers,” without modifying the original image. And so on.
All that requires a new way to analyze media and culture. Since the early 2000s, some of us (mostly from new-media studies and digital arts) have been working to meet that challenge. As far as I know, I was the first to use the terms “software studies” and “software theory” in 2001. The field of software studies gradually took shape in the mid-2000s. In 2006, Matthew Fuller, author of the pioneering Behind the Blip: Essays on the Culture of Software (Sagebrush Education Resources, 2003), organized the first Software Studies Workshop in Rotterdam. “Software is often a blind spot in the theorization and study of computational and networked digital media,” Fuller wrote in introducing the workshop. “In a sense, all intellectual work is now ‘software study,’ in that software provides its media and its context, but there are very few places where the specific nature, the materiality, of software is studied except as a matter of engineering.”
In 2007, we started the Software Studies Initiative at the University of California at San Diego, and in 2008 we held the second software-studies workshop. The MIT Press offers a software-studies series, and a growing number of books in other fields (media theory, platform studies, digital humanities, Internet studies, game studies) also help us better understand the roles software plays in our lives. In 2011, Fuller and other researchers in Britain began Computational Culture, an open-access peer-reviewed journal.
There is much more to do. One question that particularly interests me is how software studies can contribute to “big data"—analyzing vast data sets—in fields like the digital humanities, computational social science, and social computing. Here are some of the key questions related to big cultural data that software studies could help answer:
What are interactive-media “data”? Software code as it executes, the records of user interactions (for example, clicks and cursor movements), the video recording of a user’s screen, a user’s brain activity as captured by an EEG or fMRI? All of the above, or something else?
To use terms from linguistics, rather than thinking of code as language, we may want to study it as speech.
Over the past few years, a growing number of scholars in the digital humanities have started to use computational tools to analyze large sets of static digitized cultural artifacts, such as 19th-century novels or the letters of Enlightenment thinkers. They follow traditional humanities approaches—looking at the cultural objects (rather than peoples’ interaction with these objects). What has changed is the scale, not the method.
The study of software culture calls for a fundamentally different humanities methodology. We need to be able to record and analyze interactive experiences, following individual users as they navigate a website or play a video game; to study different players, as opposed to using only our own game-play as the basis for analysis; to watch visitors of an interactive installation as they explore the possibilities defined by the designer—possibilities that become actual events only when the visitors act on them.
In other words, we need to figure out how to adequately represent “software performances” as “data.” Some answers can come from the field of human-computer interaction, where researchers in academe and private enterprise study how people engage with computer interfaces. The goals of that research, however, are usually practical: to identify the problems in new interfaces and to fix them. The goals of digital humanities’ analysis of interactive media will be different—to understand how people construct meanings from their interactions, and how their social and cultural experiences are mediated by software. So we need to develop our own methods of transcribing, analyzing, and visualizing interactive experiences. Together with the Experimental Game Lab, directed by Sheldon Brown, for example, my lab analyzed the experiences of hundreds of users of Scalable City, a large-scale, complex virtual-world art installation created in Brown’s lab. One of our goals was to help future users have more challenging interactive experiences.
Who has access to detailed records of user interactions with cultural artifacts and services on the web, and what are the implications of being able to analyze these data?
From the early days of interactive human-computer interfaces, tracking users’ interaction with software was easy. Why? Because software continuously monitors inputs like key presses, mouse movements, menu selections, finger gestures over a touch surface, and voice commands.
The shift from desktop to web computing in the 1990s has turned the already existing possibility of recording and storing users’ inputs into a fundamental component of a “software-media complex.” Since dynamic websites and services (Amazon’s online store, personal blogs that use Google’s Blogger system, online games, etc.) are operated by software residing on company’s servers, it is easy to log the details of user interactions. Each web server keeps detailed information on all visits to a given site. A separate category of software and services exemplified by Google Analytics has emerged to help fine-tune the design of a website or blog.
Today social-media companies make available to their users some of the recorded information about visitors’ interactions with the sites, blogs, or accounts they own; the companies also provide interactive visualizations to help people figure out which published items are most popular, and where their visitors are coming from. However, usually the companies keep the really detailed records to themselves. Therefore, if you are one of the few social scientists working inside giants such as Facebook or Google, you have an amazing advantage over your colleagues in the academy. You can ask questions others can’t. This could create a real divide in the future between academic and corporate researchers. While the latter will be able to analyze social and cultural patterns on both supermicro and supermacro levels, the former will have only a normal “lens,” which can neither get extremely close nor zoom out to a planetary view.
Who benefits from the analysis of the cultural activities of hundreds of millions of people? Automatic targeting of ads on Google networks, Facebook, and Twitter already uses both texts of users’ posts or emails and other data, but learning how hundreds of millions of people interact with billions of images and social-network videos could not only help advertisers craft more-successful visual ads but also help academics raise new questions.
Can we analyze the code of software programs? It’s not as easy as you may think. The code itself is “big data.”
Early software programs such as 1970s video games were relatively short. However, in any contemporary commercial web service or operating system, the program code will simply be too long and complex to allow you to read and interpret it like a short story. While Windows NT 3.1 (1993) was estimated to contain four to five million source lines of code, Windows XP (2001) had some 40 million. MAC OS turned out even bigger, with OS X 10.4 (2005) code at 86 million lines. The estimated number of lines in Adobe Creative Suite 3 (which includes Photoshop, Illustrator, and a number of other popular applications to produce media) is 80 million.
The gradual move of application software to the web also brings with it a new set of considerations. Web services, apps, and dynamic sites often use multi-tier software architecture, where a number of separate modules (for example, a web client, application server, and a database) work together. Especially in the case of large commercial sites like amazon.com, what the user experiences as a single web page may involve continuous interactions between dozens or even hundreds of separate software processes.
The complexity and distributed architecture of contemporary large-scale software poses a serious challenge to the idea of “reading the code.” However, even if a program is relatively short and a cultural critic understands exactly what the program is supposed to do, this understanding of the logical structure of the program can’t be translated into envisioning the actual user experience.
The attraction of “reading the code” approach for the humanities is that it creates an illusion that we have a static and definite text we can study—i.e., a program listing. But we have to accept the fundamental variability of the actual “software performances.” So rather than analyzing the code as an abstract entity, we may instead trace how it is executed, or “performed,” in particular user sessions. To use the terms from linguistics, rather than thinking of the code as language, we may want to study it as speech.
Some researchers, like Mark Marino and others working in “critical code studies,” have been promoting nuanced, theoretically rigorous, and rich ideas about what it means to “read the code,” so my critique is aimed only at a naïve version of the idea that I sometimes encounter in the humanities.
The development of methods to study contemporary software in a way that can be discussed in articles, conferences, and public debates by nonprogrammers, is a key task for software studies. However, given both the complexity of software systems and the fact that, at least at present, only a very small number of media and cultural researchers are trained in software engineering, I don’t expect that we can solve this problem in a short time.
And yet, confronting it is crucial, not just for the academy but also for society at large. How can we discuss publicly the decisions made by Google Search algorithms, or Facebook’s algorithms controlling what is shown on our news feeds? Even if these companies made all their software open source, its size and complexity would make public discussion very challenging.
While some of the details from popular web companies are published in academic papers written by researchers working at these companies, only people with computer-science and statistics backgrounds can understand them. Moreover, many popular software services use machine-leaning technology that often results in “black box” solutions. (While the software achieves desired results, we don’t know the rules it follows.)
As more and more of our cultural experiences, social interactions, and decision making are governed by large-scale software systems, the ability of nonexperts to discuss how these systems work becomes crucial. If we reduce each complex system to a one-page description of its algorithm, will we capture enough of software behavior? Or will the nuances of particular decisions made by software in every particular case be lost?
The role of software studies is not to answer these and many other questions about our new interactive world, but rather to articulate them and offer examples of how they can be approached. And to encourage people across all disciplines to think about how software changes what they study and how they study it.
In the Phototrails project (phototrails.net), created by myself, Nadav Hochman, and Jay Chow, we visualized patterns in the use of Instagram across 2.3 million photos from 13 global cities. In the paper accompanying the project, we attempted to combine two mirror sides of software studies—thinking about software interfaces and how they influence what we do and at the same time studying large-scale behaviors of many software users. One of the key questions we raised: How much of the differences among the cities can we find, given that everybody uses the same Instagram app that comes with its own strong “message” (all photos have the same square size, and all users have access to the same set of build-in filters to make their photos more aesthetic in the same ways). While we did find small but systematic differences in the photos from each city, the use of Instagram software itself was remarkably consistent.
How does the software we use influence what we express and imagine? Shall we continue to accept the decisions made for us by algorithms if we don’t know how they operate? What does it mean to be a citizen of a software society? These and many other important questions are waiting to be analyzed.
Lev Manovich is a professor of digital humanities and computer science at the Graduate Center of the City University of New York and director of the Software Studies Initiative at the California Institute for Telecommunications and Information Technology (Calit2) and the Graduate Center. His most recent book is Software Takes Command: Extending the Language of New Media (Bloomsbury Academic, 2013).
